之前写过一篇fastjson漏洞文章,但是当时在复现利用链的过程中一直没有弹出计算器,而且利用链的代码单步调试也没有给出来,这次我要通过底层代码把漏洞实现过程展现出来。
fastjson漏洞demo
上次不是没有弹出计算器吗,这次我先把可以弹出计算器的漏洞demo先讲解一下。
- 创建一个普通类Person
import java.util.Properties;
//创建一个普通类
public class Person {
private String name;
private int age;
private String sex;
private Properties properties;
public Person() {
System.out.println("构造方法");
}
//Setter Getter方法
public String getName() {
System.out.println("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
public int getAge() {
System.out.println("getAge");
return age;
}
public String getSex(){
System.out.println("getAddress");
return sex;
}
public Properties getProperties() throws Exception {
System.out.println("getProperties");
Runtime.getRuntime().exec("open -a /System/Applications/Calculator.app");
return properties;
}
}
- 反序列化测试
import com.alibaba.fastjson.JSON;
public class Demo {
public static void main(String[] args){
String jsonstring ="{\"@type\":\"com.FastjsonDemo.Person\",\"age\":18,\"name\":\"lili\",\"address\":\"china\",\"properties\":{}}";
//JSON.parseObject() 方法将 jsonstring 字符串解析并转换为一个通用的 Object 对象
Object obj = JSON.parseObject(jsonstring, Object.class);
System.out.println(obj);
}
}
- 测试结果
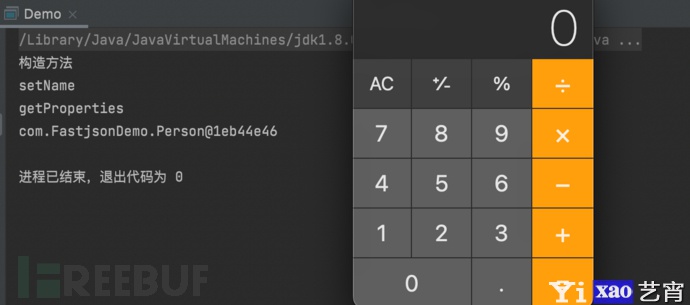

代码调试讲解
- 我们在JSON.parseObject位置处打上断点
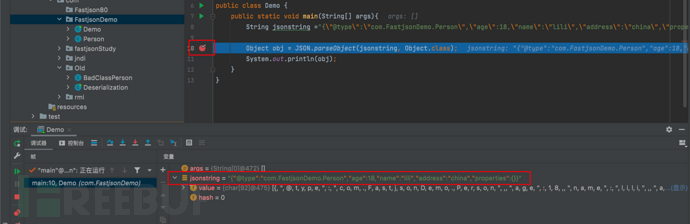
- f7步入,进入到parseObject(String text, Class clazz)方法中,text为要解析的JSON字符串;clazz为要转换的目标类型,Class中的T为范型参数,表示要转换成的具体类型。在这个方法的实现中,它再次调用自己,通过递归无限循环调用自身。
public static T parseObject(String text, Class clazz) {
return parseObject(text, clazz);
}
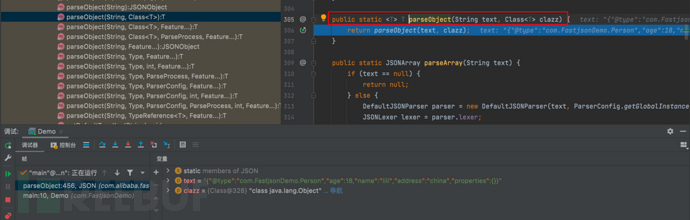
- f7继续步入,进入parseObject(String json, Class clazz, Feature… features)方法,这里又是一个重载方法,接受了三个参数:一个JSON字符串json、目标类型的Class对象clazz和可选的特性(features)数组。在方法的实现中,它掉用了另一个重载的\’parseObject\’方法,将解析过程委托给它。这个新的重载方法接受了更多的参数,包括:ParserConfig对象、ParseProcess对象以及默认的解析特性(DEFAULT_PARSER_FEATURE)。
public static T parseObject(String json, Class clazz, Feature... features) {
return parseObject(json, clazz, ParserConfig.global, (ParseProcess)null, DEFAULT_PARSER_FEATURE, features);
}
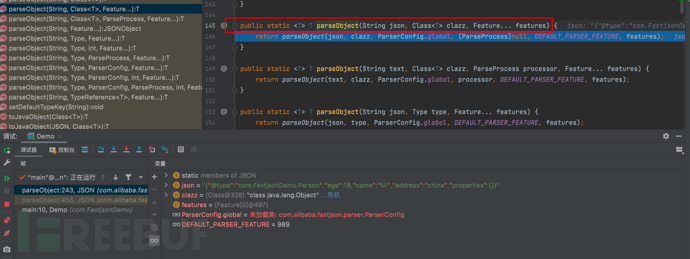
- f7步入到 public static T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor, int featureValues, Feature… features) {…}方法中
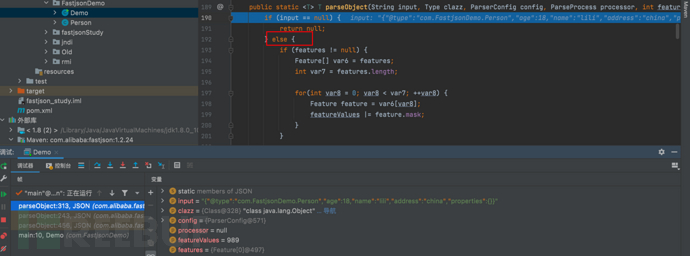
- 我们详细看一下这段代码,目的是将输入的input字符串解析为指定类型 \’clazz\’ 的java对象。
public static T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor, int featureValues, Feature... features) {
//input为{"@type":"com.FastjsonDemo.Person","age":18,"name":"lili","address":"china","properties":{}}
if (input == null) {
return null;
} else {
//features为Feature[0]@497
if (features != null) {
Feature[] var6 = features;
//定义特性数组长度var7
int var7 = features.length;
for(int var8 = 0; var8 < var7; var8) {
//获取当前索引var8位置的特性对象,并将其复制给变量feature
Feature feature = var6[var8];
//使用按位或操作符(|=)将当前特性的掩码(feature.mask)与featureValues进行按位或运算,并将结果重新赋值给featureValues
featureValues |= feature.mask;
}
}
//创建一个DefaultJSONParser对象parser,用于解析JSON字符串。这个对象使用传入的输入字符串、配置对象config和特性值featureValues进行初始化。
DefaultJSONParser parser = new DefaultJSONParser(input, config, featureValues);
//处理解析过程中的处理器processor,此时processor为null
if (processor != null) {
if (processor instanceof ExtraTypeProvider) {
parser.getExtraTypeProviders().add((ExtraTypeProvider)processor);
}
if (processor instanceof ExtraProcessor) {
parser.getExtraProcessors().add((ExtraProcessor)processor);
}
if (processor instanceof FieldTypeResolver) {
parser.setFieldTypeResolver((FieldTypeResolver)processor);
}
}
//解析JSON字符串并得到解析结果对象
T value = parser.parseObject(clazz, (Object)null);
//处理解析结果中的后续任务
parser.handleResovleTask(value);
//关闭解析器
parser.close();
//返回解析结果对象
return value;
}
}
- 跟着f8步过代码
- 首先执行循环
for(int var8 = 0; var8 < var7; var8) {
Feature feature = var6[var8];
featureValues |= feature.mask;
}
- 随后跳转创建DefaultJSONParser对象
DefaultJSONParser parser = new DefaultJSONParser(input, config, featureValues);
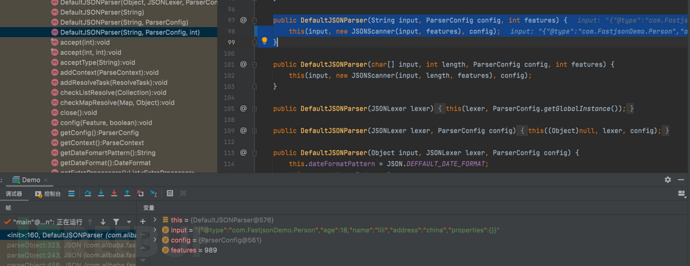
- 继续执行processor的判断,因为processor为空,跳过判断
if (processor != null) {...}
- 随后进行解析JSON字符串并得到解析结果对象
这里是使用解析器parser对JSON字符串进行解析,并将解析结果赋值给变量value。解析的目标类型由参数clazz指定,该方法返回了一个泛型类型T的对象。
T value = parser.parseObject(clazz, (Object)null);
- 直接f8跳转下一步,可以发现计算器被弹出来,造成命令执行
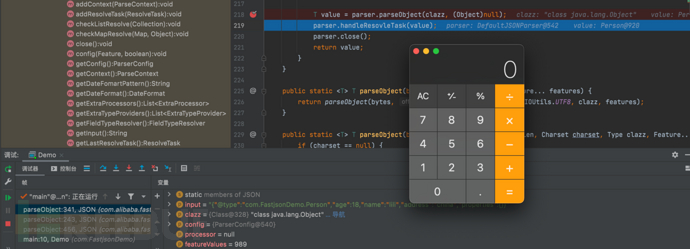
- 重点调试parser.parseObject(clazz, (Object)null)代码
T value = parser.parseObject(clazz, (Object)null);
- f7步入代码
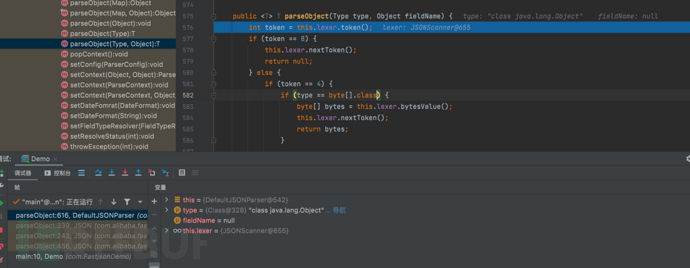
public T parseObject(Type type, Object fieldName) {
//获取当前JSON的token类型
int token = this.lexer.token();
if (token == 8) {//如果当前token是JSON的null值(8代表null)
this.lexer.nextToken();//跳过null值解析
return null;
} else {
if (token == 4) {//如果当前token是JSON的字符串值(4代表字符串)
if (type == byte[].class) {//判断期望类型是否为 \'byte[]\'
byte[] bytes = this.lexer.bytesValue();//如果是,获取字节数组值
this.lexer.nextToken();//跳过字符串值的解析
return bytes;//返回字节数组值
}
if (type == char[].class) {//判断其我想是否为 \'char[]\'
String strVal = this.lexer.stringVal();
this.lexer.nextToken();
return strVal.toCharArray();//将字符串转换为字符数组并返回
}
}
//以上都不满足,根据期望类型获取相应的\'ObjectDeserializer\',并使用它来解析
ObjectDeserializer derializer = this.config.getDeserializer(type);
try {
return derializer.deserialze(this, type, fieldName);//通过config(ParserConfig对象)获取相应类型的反序列化器,并调用deserialze方法进行解析。该方法会根据给定的JSON类型和字段名,将当前解析器作为参数,返回解析后的Java对象。
} catch (JSONException var6) {
throw var6;
} catch (Throwable var7) {
throw new JSONException(var7.getMessage(), var7);
}
}
}
- 初始化token值为12

- 不满足if循环。会步入ObjectDeserializer derializer = this.config.getDeserializer(type);
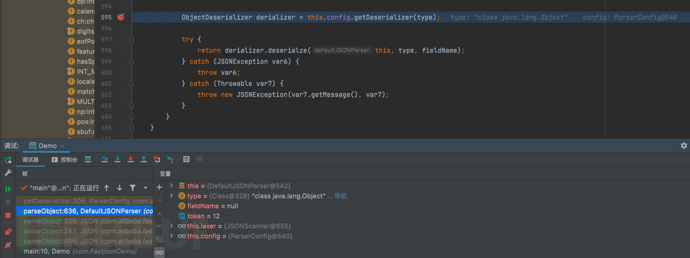
- 分析这段代码实现细节
ObjectDeserializer derializer = this.config.getDeserializer(type);
- f7步入,这段代码是 \’ParseConfig\’ 类中的 \’getDeserializer(Type type)\’方法,目的是根据给定的类型(Type)获取相应的反序列化器(ObjectDeserializer)。初始 derializers 为默认值IdentityHashMap@659,derializer的值为null。随后进行一个缓存类型的判断:(1)如果类型type属于 \’Class\’ 类型,调用 getDeserializer(Class, Type)方法,传入类型(Class)和类型(Type)进行处理;(2)如果类型(Type)是ParameterizedType类型,获取原始类型(RawType)。随后做了一个三元运算符判断:如果原始类型是Class类型就调用getDeserializer(Class, Type)方法,对传入原始类型(Class)和类型(Type)进行处理;否则就递归调用getDeserializer(Type)方法,对传入原始类型(RawType)进行处理。(3)其他情况就返回默认的反序列化器 \’JavaObjectDeserializer.instance\’。
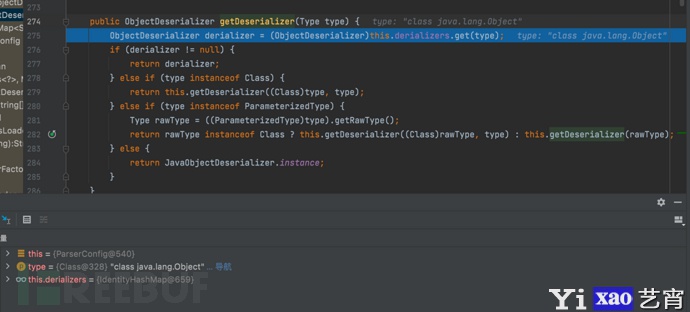
- f7继续步入后是一段基于身份比较hash映射的 \’get\’ 方法
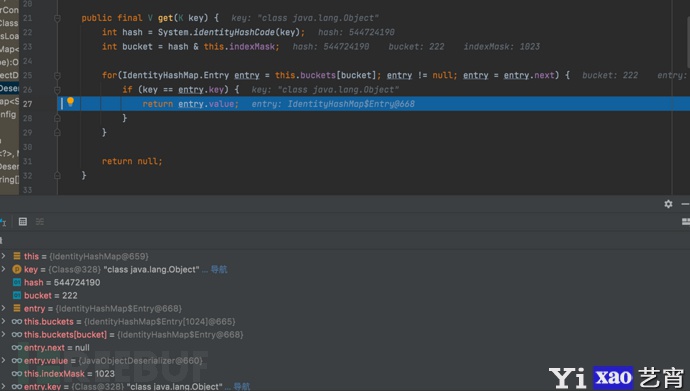
- 最终获取的derializer值为JavaObjectDeserializer@660
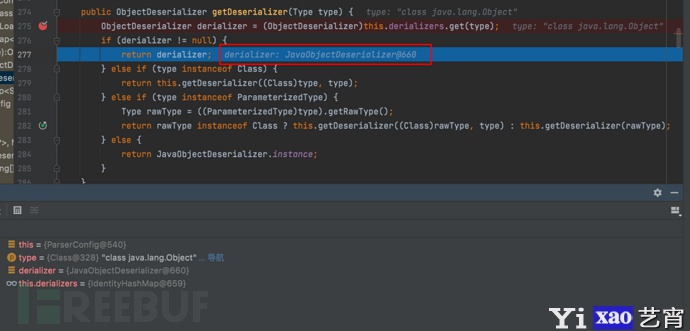
- 返回反序列化器具体值:当前对象DefaultJSONParser@542、类型type为Object对象、fieldName字段名为null、config属性值为ParseConfig@540
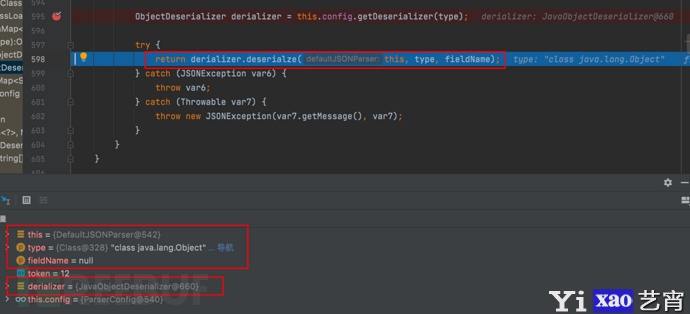
- 返回值的具体实现可以f7继续步入查看
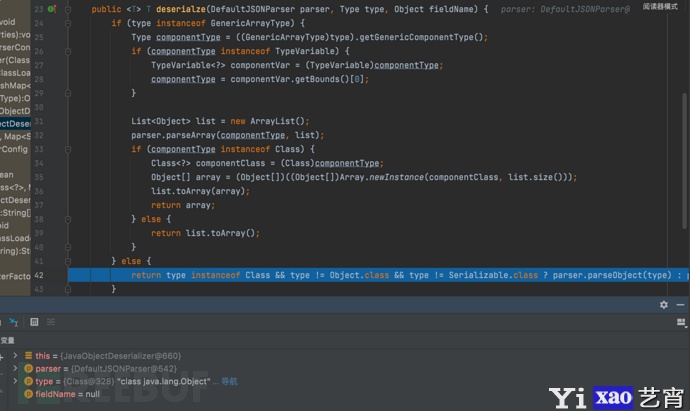
- 底层是一个JSON解析器的 \’parse\’ 方法,lexer的初始化默认值为JSONScanner@655
public Object parse(Object fieldName) {
JSONLexer lexer = this.lexer;
switch(lexer.token()) {
case 1:
case 5:
case 10:
case 11:
case 13:
case 15:
case 16:
case 17:
case 18:
case 19:
default:
throw new JSONException("syntax error, " lexer.info());
case 2:
Number intValue = lexer.integerValue();
lexer.nextToken();
return intValue;
case 3:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken();
return value;
case 4:
String stringLiteral = lexer.stringVal();
lexer.nextToken(16);
if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(stringLiteral);
try {
if (iso8601Lexer.scanISO8601DateIfMatch()) {
Date var11 = iso8601Lexer.getCalendar().getTime();
return var11;
}
} finally {
iso8601Lexer.close();
}
}
return stringLiteral;
case 6:
lexer.nextToken();
return Boolean.TRUE;
case 7:
lexer.nextToken();
return Boolean.FALSE;
case 8:
lexer.nextToken();
return null;
case 9:
lexer.nextToken(18);
if (lexer.token() != 18) {
throw new JSONException("syntax error");
}
lexer.nextToken(10);
this.accept(10);
long time = lexer.integerValue().longValue();
this.accept(2);
this.accept(11);
return new Date(time);
case 12:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return this.parseObject((Map)object, fieldName);
case 14:
JSONArray array = new JSONArray();
this.parseArray((Collection)array, (Object)fieldName);
if (lexer.isEnabled(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
case 20:
if (lexer.isBlankInput()) {
return null;
}
throw new JSONException("unterminated json string, " lexer.info());
case 21:
lexer.nextToken();
HashSet
内容出处:FreeBuf.COM,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/procedure/30587.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
MySQL经典案例分析
一、 前言 前面说了一些概念,比如事务、MVCC、锁等,对Innodb有了个大概了解。 这次通过一个经典案例来将这些串起来回顾下。 回到顶部 二、经典案例 面试官:select *…
-
Ansible playbook 编程
主机规划 添加用户账号 说明: 1、 运维人员使用的登录账号; 2、 所有的业务都放在 /app/ 下「yun用户的家目录」,避免业务数据乱放; 3、 该用户也被 ansible …
-
程序员用css写出这样的效果,现在能用纯css写出这样效果的能有几人呢?
程序员用css写出这样的效果,现在能用纯css写出这样效果的能有几人呢? 现在很多人都觉得前端基础很容易,就那么些东西,都大概了解基础后就不管了,认为前端开发只有js,其实不是,不…
-
WordPress制作读者墙,用户评论排行榜
所谓的读者评论排行榜,就是展示在本博客评论最多的几个读者的头像(如果你还没有自己的个性头像或不知道怎么设置头像,请点此设置通用头像),按照读者的评论数进行排名,同时附上他们的博客网…
-
基于Redis消息的订阅发布应用场景
基于Redis消息的订阅发布应用场景 1.应用背景 在物联网采集管控系统中,前后端隔离的情况下,前端通过表单(比如按钮,开关,表格等)输入数据到数据库(比如MySql,通过WEBA…
-
MPlatform:OpsMind前端低代码开发平台
简介 MPlatform,是 OpsMind 一个快速搭建 WEB 站点的平台。在开发过程中,只需要进行简单的组件拼接,就能完成整站的搭建任务,与传统开发方式相比,省去了很多编写代…
-
Flutter适配移动端和web不同尺寸
用到的库 这款开源的库,可以实现不同屏幕尺寸的适配.responsive_builder 使用方法 1. pubspec.yaml引入库 responsive_builder: ^…
-
Ciphey:Python全自动解密解码神器
Ciphey 是一个使用自然语言处理和人工智能的全自动解密/解码/破解工具。 简单地来讲,你只需要输入加密文本,它就能给你返回解密文本。就是这么牛逼。 有了Ciphey,你根本不需…
-
Springboot+Python之RSA加解密方案
1、RSA java实现加解密 import java.io.ByteArrayOutputStream; import java.security.Key; import jav…
-
通过javascript将图片延迟加载实现方法及代码
什么是图片延迟加载 图片延迟加载(Lazy Load)是一种优化网页性能的技术,它可以延迟加载页面中的图片,使网页的加载速度更快,提升用户的体验。具体实现就是在网页中,把页面中的图…