如何设计一个简单的新闻聚合产品?文章介绍了制作极简的新闻聚合产品的7步骤,好奇的你和我一起来看看。


你知道在三四线的县城,用户在哪里看新闻么?不是在今日头条里,而是在微信中的那个腾讯新闻里。这是我在安徽青阳做用户调研时绝大多数给我的回答。这或许说明一点:用户没有像设计师那样的洁癖,期望每一个app都有明确的边界。谁说不能在一个社交app里看新闻,我还要加一句,谁说不能在本地头条(我正在负责的产品)里看全国头条。说是这么说了,但是心里清楚这只是产品的外延,既然是外延就应该追求做产品的性价比,所以才有了这个极简的新闻聚合产品。
先定个产品的小目标:通过全技术的方式,给用户提供一个高频更新的新闻列表,运营可进行微调干预。
整个过程7步完成,对,就是七步成诗那七步。
1.构建标签库
标签库其实就是词条库,词条哪里来?或者换一个问法,互联网上谁最懂中文?答案当然是百度咯。跑到百度百科首页一看,我们要的东西就躺在下面的红框里。
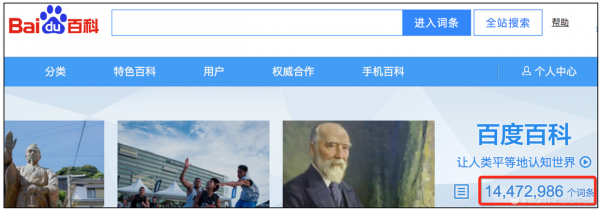
那我们还客气啥,爬呀,等等,1400万是不是有点太多了?那我们就去掉一点吧,只留下名词好了,这样可以把词库控制在百万量级。
2.抓取新闻
接下来,就是抓新闻,新闻哪里有,找门户网站呗,公众号app就算了,费时费力,爬PC站不是一样的嘛,以体育为例,我们可以挑选新浪体育,搜狐体育,凤凰体育,还有什么体育?你也看出来了其实我对体育无感,这里就假设有10个体育专题网站吧。
我们要抓的是热门新闻,啥叫热门,出现在第一屏的就是热门,所以我们抓取的时候,只抓取首屏新闻。结果就是我有了一堆标题和链接,还有链接后面的正文。
3.建立新闻和标签的关联
现在到了建立新闻和标签关联的时候了,首先当然是要分词,怎么分?呃,这个好像有很多自然语言词库的吧,你自己去找吧,分词完了之后,计算各个词的出现频率,出现频率越高说明它越可能是这篇文章的关键词。出现在标题里的词是不是比出现在正文里的词更重要呢?所以你可以把标题里的词加个N倍权重,N等于几?关注我私信我就告诉你。
这里分出来的词,其实就是标签库里的标签。这样每一篇文章就有一个对应的词频由高到低的标签列表了,太长了也没用,就取TOP5吧。
这里有个问题留给你,既然文章要分词,文章分出来的词直接做词库不就好了,为啥要去百度爬呢?答案还是要关注我私信我才告诉你。
4.标签热度排序
现在我们为体育频道选择了10个数据源(就是新浪体育这样的网站),每个数据源下抓了50篇文章,每篇文章都有5个标签,现在我们要看哪个标签最热了。我们的方式简单得很,否则怎么说我们设计了一个极(jian)简(lou)的产品呢,方法是如果一个标签在一个数据源出现了,就加1,在10个数据源都出现了那就是10。通过这种方式你会得到每一个标签的值,这个值除以数据源总数就是“热度值”,在我们这里就是0.1到1之间的分布。
这个时候运营的妹子来乱入了,她说她的特长就是八卦,而且是先人一步的八卦,让我们千万要相信她判断热点的是否会大热的能力。这句话的意思是:她想来人肉预先提升一个标签的热度值,虽然现在它还没有大热。嗯,平常关系辣么好,我不信也得做个姿势选择相信,于是就有了下面的线框。她可以调整一个标签次的热度值。
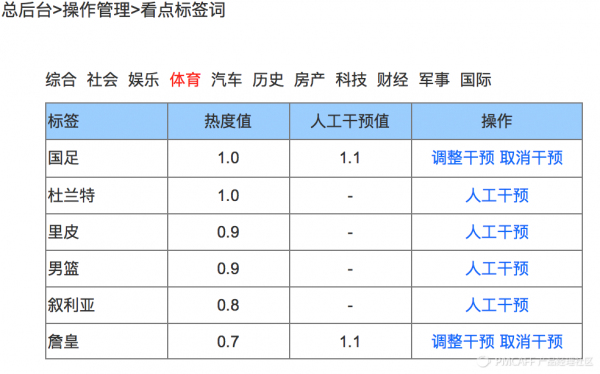
呀,最后怎么还有两个词连接在一起的?实际上多个词比单个词更接近于一个热点事件。当然对于这种二元词,计算方式和一元词略有不同,细节此处不展开。
5.文章按频道排好序
到这里我们已经有了标签的热度排序,那文章的热度怎么算呢?文章不是有5个标签嘛,那个最高热度值标签的热度就是文章的热度。
实际上热度只是文章的一个维度,要给文章排序,你自然还会想到以下的几个维度:
质量分:一篇结构完整、图片丰富的文章显然具有更高的质量时效分:越新的越优先,大家是来看新闻的嘛。
具体算法上可以用高斯衰减,比如72小时内基本无衰减,超过72小时后每过12小时就衰减一点。说到衰减,最近看了采铜的效益半衰期理论感觉颇为受用,大意是:一个人管理自己日常的行为,可以考虑这个行为对自己长期受用程度来衡量,有些事情效益半衰期很长比如读书和健身,就应该多做,另外一些事情效益半衰期很短比如游戏,就可以少做。
扯一扯防松一下,接回来说。
文章要排序,就是看这3个因子,编一个数据公式把:热度分,质量分,时效分串起来计算出一个数值就ok了,想要公式?好像不是很方便哎,再说你那么聪明,自己也能搞出来。
6.按频道权重整合输出
文章有了排序,下一步直接输出么?可是当前我们只有一个全国新闻频道,细分分频道啊,个性化呀那都是以后的事情,极简系统就是千人一面的啦。所以下一步我们要定一下各种频道的内容如何混在一起。这个没有啥技术含量,就是给各个频道定个权重,然后按这个权重计算个比例去混合就好了。技术上可确保,用户看的越多,实际比例就越接近预先定义的权重分布
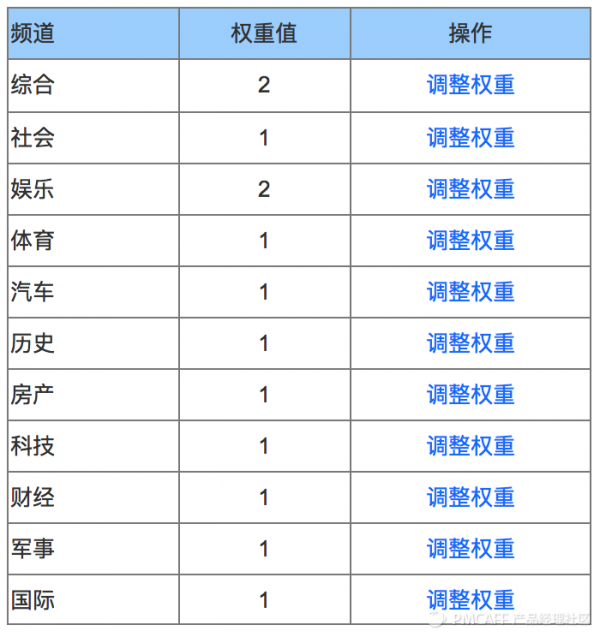
咦,好像漏了说文章属于什么频道的了。在我们第2步里决定去哪些数据源抓新闻的时候就决定了。每个数据源都对应了一个频道, 那么从这个数据源里抓取的文章也就对应了一个频道。主要的几个频道是:社会、娱乐、体育、汽车、历史、房产、科技、财经、军事、国际。
7.过滤用户已读
终于来到了最后一步,作诗也没这么累啊。
对于全国新闻这种用之不尽、取之不竭、看过就忘、不看两遍的题材来说,给用户最好的阅读体验就是每次都给他没看过的,过滤掉所有已经看过的。
那如何尽可能简洁地实现呢?简洁的本质就是照顾主要场景忽略次要场景。主要场景是用户每几个小时打开一次,打开一次看十来分钟。如果我们每小时爬取的新闻数足够多,衰减做的足够高,是否需要过滤已读都是可以商量的了。实操里,我们还是记录了用户的已读信息,然后一次请求里返回足够多的新闻,比如10个频道每个频道300篇,也就是3000篇,然后再过滤一下,性能上完全可接受,主要场景里也不会出现新闻看完的情况。
总结一下
在设计这个热门新闻列表产品的过程中,主要是几个点:
新闻的热度本质上是标签的热度,标签用百度的词条标签的热度其实就是同时出现在多个网站上的频度文章的排序就是文章热度分,质量分,时效分的综合打分作者:大中,内容类创业公司的产品总监,此前在阿里5年,负责过虾米音乐等产品。平常关注内容、社区和电商类产品。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/operation/2695.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
物联网在零售领域的8个创新案例
物联网在零售业的另一个创新例子是智能货架。零售商花费大量时间和精力来跟踪商品,以确保它们永远不会缺货,并确保商品不会错放在无关货架上。智能货架自动执行这两项任务,同时检测潜在的盗窃行为。
-
只有开放才能挽救社交网站
在2.0时代,社交网站(SNS)的崛起,以社交和分享为核心理念的网络文化风靡,互联网商们自觉地将SNS作为应对未来的重要法宝。无论是对于用户还是第三方程序提供商,封闭、单一就意味着失败。在一个开放的平台上进行无缝隙的分享,使一种服务体验在同一平台上以几何的数字增长,是SNS雄踞互联网的利器。开放平台战略,就是将这一特性发挥到极致的根本。
-
基于某生鲜APP业务的数据仓库搭建过程
生鲜app搭建数据仓库是非常必要的,它需要提升供应链管理能力和数据的计算的准确性和时效性。那么,要怎么去进行一个数据仓库的搭建呢?本文给大家分享一下搭建的过程~ 某生鲜APP搭建数…
-
直播带货2.0时代来临
所有的商业模式,都需要根据市场的变化,进行更新迭代,直播带货也是如此。 如果你目前做直播带货,只能赔钱赚吆喝,那么说明你还停留在直播1.0时代。 直播带货1.0时代,是以依托电商平…
-
网站运营“小众软件”躺赚的玩法
一)规则 小说的用户量极大,每本小说都是一个大IP,每天有无数次搜索,做个小说网站岂不是大赚? 版权大棒,赔钱倒闭。 美女写真的爱好者极多,做个写真图片站,卖VIP一定能大赚? 涉…
-
企业网络营销中链接策略实施的重要性
企业网络营销推广过程中应积极制定长期的链接策略,反向链接是稳定排名的一个重要的因素。大家可以观察一些排名靠前的网站都是有反向链接所支持,相信这种链接的深度算法暂时不会改变,但链接策略却是应该分层次和分技巧的进行。
-
利用最不起眼的营销模式“利他主义”,成就晨光文具的巨头梦想
晨光文具如今已经为文具界的巨头,学校周边的文具店都打着”晨光文具”的招牌。2019年公司营收111亿元,超过7.8万家零售店,站稳”中国文具第一…
-
网站建设前的10点规划
随着互联网逐步发展成熟以及90后成为当今网络最大用户群体时候,这个时候我们做一个网站就要给一个网站进行良好的网站规划。因为垃圾站的生存余地越来越小。在建立网站前应明确建设网站的目的,确定网站的功能,确定网站规模、投入费用,进行必要的市场分析等。
-
网站流量与盈利模式提高中探索
工作中,客户经常咨询,对于一个网站来说,“是应该先全心全意做大流量,还是边做流量边进行盈利模式的探索,本身就是一个特别艰难的抉择,看上去,它们就像两条永远没有交汇点的路。”